Almacenamiento de AWS
Amazon S3 Simple Storage Service
El almacenamiento S3 te permite almacenar y recuperar cantidades ilimitadas de datos desde cualquier parte del mundo en cualquier momento. Puedes utilizar S3 para almacenar cualquier tipo de fichero.
Puedes implementar control de acceso y encriptación para restringir el acceso a tus ficheros a direcciones IP específicas.
Objetos y buckets
S3 se diferencia de EBS (Elastic Block Storage) de que en lugar de almacenar bloques de datos en bruto como EBS, S3 almacena objetos de datos. Cada objeto puede tener un tamaño de hasta 5TB.
El nombre de un objeto se denomina clave y puede tener una longitud máxima de 1.024 bytes. La clave de un objeto puede estar formada por caracteres alfanuméricos y algunos caracteres especiales.
Los objetos S3 se almacenan en un contenedor llamado bucket que es en esencia un sistema de ficheros plano.
Un bucket puede almacenar un número ilimitado de objetos.
Los nombres de los buckets son únicos a nivel global aunque cada bucket y por ende los objetos que almacen sólo pueden existir en una única región. Esto ayuda a la latencia, seguridad, coste y cumplimientos legales.
Puedes usar cross-region replication para copiar el contenido de un objeto de un bucket de una región al bucket de otra región, pero aún así cada copia del objeto original seguirá siendo única. AWS nunca mueve objetos entre regiones.
Como es de esperar, S3 tiene un coste. No se te cobra por subir datos a S3, pero puede que se te cobre cuando descargue datos.
Por ejemplo, en la región este de Estados Unidos, puede descargar hasta 1 GB de datos al mes sin coste alguno. Más allá de eso, la tarifa es de 0,09 dólares o menos por gigabyte.
S3 también te cobra una tarifa mensual en función de la cantidad de datos que almacenes y la clase de almacenamiento que utilices.
Durabilidad y disponibilidad
Se dice que los objetos que deben permanecer intactos y libres de borrado o corrupción inadvertidos necesitan una alta durabilidad, que es el porcentaje de probabilidad de que un objeto no se pierda a lo largo del transcurso de un año. Cuanto mayor sea la durabilidad del medio de almacenamiento, menor será la probabilidad de perder un objeto.
Los datos también tienen diferentes requisitos de disponibilidad. La disponibilidad es el porcentaje de tiempo que un objeto estará disponible para su recuperación.
El nivel de durabilidad y disponibilidad de un objeto depende de su clase de almacenamiento. S3 ofrece seis clases diferentes de almacenamiento a diferentes precios. S3 cobra un coste de almacenamiento mensual en función de la cantidad de datos que almacene y de la clase de almacenamiento que utilice.
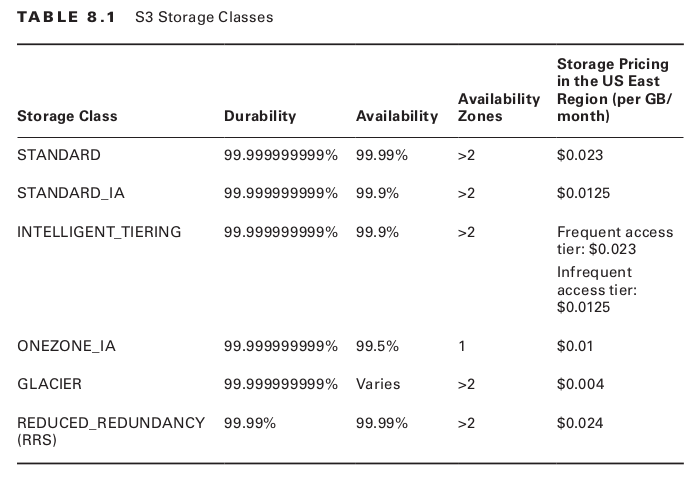
En función de la durabilidad y disponibilidad que deseemos, AWS clasifica los objetos en 3 grupos diferentes, a saber:
Frequently Accessed Objects: objetos con una mínima latencia a la que se accede frecuentemente:
STANDARD: este es el almacenamiento por defecto, ofrece los mayores niveles de durabilidad y disponibilidad y los objetos siempre son replicados a través de al menos las 3 últimas Availability Zones de tu región.
REDUCED_REDUNDANCY (RRS): está pensado para aquellos datos que pueden ser facilmente reemplazados. Tiene el menor nivel de durabilidad pero el mismo nivel de disponibilidad que STANDARD. AWS no recomienda usarlo.
Infrequently Accessed Objects: ofrece un acceso con una latencia de milisegundos y una alta durabilidad, pero la menor disponibilidad de todas las clases. Están diseñadas para objetos que tengan un tamaño mínimo de 128 KB. Se pueden almacenar objetos más pequeños, pero cada uno se facturará como si fuera de 128 KB.
STANDARD_IA: está diseñado para datos importantes que no pueden ser recreados. Los objetos son almacenados en varios Availability Zones y tienen una disponibilidad del 99.9%
ONEZONE_IA: los objetos solo se almacenan en una única Availability Zone y por lo tanto tienen los niveles más bajos de disponibilidad (99.5%)
GLACIER: diseñado para almacenar objetos que rara vez van a necesitar ser recuperados. Estos objetos tienen un ciclo de vida largo y en caso de ser recuperados no se hace en tiempo real. En su lugar hay que iniciar una petición de restauración y esperar a que haya terminado. El tiempo que le cueste a la restauración dependerá de la opción que hayas elegido pero se moverá entre 1h y 12h.
Both Frequently and Infrequently Accessed Objets: S3 ofrece una solución que es una mezcla de las anteriores:
INTELLIGENT_TIERING: S3 mueve los objetos entre los diferentes niveles en función del histórico pasado y buscando la solución más barata. Si un objeto no ha sido accedido desde los últimos 30 días entonces es movido automáticamente a una capa más barata de infrequent access object. En el momento en el que el objeto es accedido de nuevo se vuelve a mover a una capa superior de frequently access object automáticamente.
Permisos de acceso
Por defecto, los objetos que pones en un bucket S3 son innacesibles para cualquier persona fuera de tu cuenta AWS.
S3 ofrece las siguientes formas de manejar los permisos de acceso a tus objetos de S3:
Bucket policies: es un conjunto de políticas basadas en recursos que se aplica a un bucket. Puedes utilizar las políticas de buckets para conceder acceso a todos los objetos dentro de el o sólo a objetos específicos. También puedes controlar qué cuentas pueden leer, escribir o eliminar objetos. También puedes conceder acceso de lectura anónimo para que un objeto, como una página web o una imagen, esté disponible para a todo el mundo en Internet.
User policies: puedes utilizar éstas políticas para conceder a una IAM el acceso principal a un bucket S3. A diferencia de las políticas de buckets en las que se aplicaban al bucket directamente, tu puedes aplicar políticas de acceso solo a una cuenta IAM prinicipal. Ten en mente que no puedes usar las políticas de usuario para conceder acceso anónimo a un objeto.
Bucket y Listas de Control de Acceso (ACL): estos son métodos hereados que han sido reemplazados por las opciones anteriores aunque se pueden seguir usando las ACLs.
Encriptación
S3 no cambia el contenido de un fichero cuando lo subes, eso significa que si subes un fichero con datos personales, esos datos se almacenan en texto plano sin encriptación.
Usando las políticas de acceso correctas puedes llegar a proteger el fichero pero lo recomendable sería encriptarlo. S3 te ofrece dos formas para encriptar:
Server-side encryption: cuando creas un objeto S3 encripta el objeto y almacena el contenido encriptado. Cuando lo recuperas, S3 lo desencripta y lo distribuye en texto plano. Esta opción es la más sencilla de implementar y no necesita de llaves de encriptación.
Client-side encryption: el cliente es el encargado de encriptar los datos antes de subirlos y de desencriptarlos cuando S3 los distribuye. Esta opción es más complicada ya que si pierdes las llaves de encriptación no podrás recuperar el fichero y desencriptarlo.
Versionado
Sin el control de versiones, si se sube un objeto con el mismo nombre que un objeto existente en el mismo bucket, el contenido del objeto original se sobrescribirá.
Pero si habilita el control de versiones en el bucket y luego se sube un objeto con el mismo nombre que un objeto existente, S3 simplemente creará una nueva versión de ese objeto. La versión original permanecerá intacta y disponible.
Si elimina un objeto en un cubo en el que el control de versiones está desactivado, el contenido del no se elimina. En su lugar, S3 añade un marcador de eliminación al objeto y lo oculta de la vista de la consola del servicio S3.
Por defecto el versionado está desactivado en los buckets S3 y no existe límite en el versionado de cualquier objeto que puedas almacenar.
Puedes eliminar versiones a mano o usando las configuraciones de ciclo de vida.
Configuraciones del ciclo de vida de objetos
Dado que S3 puede almacenar cantidades prácticamente ilimitadas de datos, es posible que se acumule una factura bastante grande si subes continuamente objetos pero nunca borras ninguno. Esto podría ocurrir si tienes una aplicación aplicación que sube frecuentemente archivos de registro a un bucket.
También puedes gastar más de lo necesario si mantienes los objetos en una clase de almacenamiento más cara cuando una más barata podría satisfacer sus necesidades.
Las configuraciones del ciclo de vida de los objetos pueden ayudarte a controlar los costes, mover objetos a diferentes clases de almacenamiento o eliminarlos después de un tiempo.
Las reglas de configuración del ciclo de vida de los objetos se aplican a un cubo y consisten en uno o ambos de los siguientes tipos de acciones:
Acciones de transición: mueven objetos a un tipo de almacenamiento S3 diferente cuando alcanzan cierta edad. Por ejemplo puedes crear una regla para que mueva los objetos de la capa STANDARD a la capa STANDARD_IA después de 90 días.
Acciones de expiración: estas acciones pueden eliminar automáticamente objetos cuando alcanzan cierta edad.
➜ Escritorio > aws s3 ls
2021-10-17 11:08:46 gorkamubucket-test-001
➜ Escritorio > touch ejemplo.txt
➜ Escritorio > aws s3 mv ejemplo.txt s3://gorkamubucket-test-001
move: ./ejemplo.txt to s3://gorkamubucket-test-001/ejemplo.txt
➜ Escritorio > aws s3 ls
2021-10-17 11:08:46 gorkamubucket-test-001
➜ Escritorio > aws s3 ls s3://gorkamubucket-test-001
2021-10-17 11:11:07 0 ejemplo.txt
➜ Escritorio > aws s3 rb s3://gorkamubucket-test-001 --force
delete: s3://gorkamubucket-test-001/ejemplo.txt
remove_bucket: gorkamubucket-test-001
➜ Escritorio > aws s3 ls
...S3 Glacier
S3 Glacier ofrece un archivado a largo plazo de los datos a los que se accede con poca frecuencia a un coste increíblemente bajo coste.
La idea es cargar grandes cantidades de datos para un almacenamiento duradero a largo plazo con la esperanza de que nunca los necesite, pero con la expectativa de que estarán allí en el improbable caso de que los necesites.
Glacier garantiza una durabilidad del 99,999999999% durante un año determinado que es el mismo nivel de durabilidad que la clase de almacenamiento GLACIER en S3.
Con Glacier, usted almacena uno o más archivos en un archivo, que es un bloque de información.
Aunque se puede almacenar un solo archivo en un archivo, el enfoque más común es combinar varios archivos en un archivo .zip o .tar y cargarlo como un archivo. Un archivo puede tener entre 1 byte y 40 TB.
Glacier almacena los archivos en una bóveda, que es un contenedor específico de la región (muy parecido a un cubo de S3) que almacena los archivos. Los nombres de las bóvedas deben ser únicos dentro de una región, pero no tienen que ser únicos a nivel mundial.
Opciones de recuperación
Debido a que Glacier está diseñado para el archivado de larga duración, no ofrece acceso en tiempo real a esos archivos.
Descargar un archivo de Glacier es un proceso de dos pasos que requiere la inicialización de un trabajo de recuperación y después la descarga del archivo cuando se haya terminado el trabajo. El cantidad de tiempo que le cueste recuperar el archivo dependerá de una de las opciones que hayas seleccionado:
Expedited(Acelerada): en momentos de gran demanda, las recuperaciones aceleradas suelen completarse entre 1 y 5 minutos, aunque los archivos de más de 250 MB pueden tardar más. En la región este de Estados Unidos, el coste es de 0,03 dólares por gigabyte. Opcionalmente, se puede adquirir una capacidad provisionada para garantizar que las recuperaciones aceleradas se realicen en el momento oportuno.
Standard: recupera los archivos entre 3 a 5 horas. Esta es la opción por defecto y cuesta 0,01 dólares por gigabyte en la región este de EEUU.
Bulk: es la opción más económica, 0,0025 dólares por gigabyte en la región este de EEUU y tarda en completarse entre 5 y 12 horas.
AWS Storage Gateway
Este servicio hace que sea sencillo conectar el almacenamiento de tus servidores on-premise con el almacenamiento de AWS.
Debido a que usa protocolos usados por la industria no es necesario instalar software adicional en tus servidores. En su lugar hay que aprovisionar una máquina virtual de AWS Storage Gateway y conectar contra ella tus servidores on-premise.
Esta máquina virtual puede correr en VMWare, ESXi o Microsoft Hyper-V hypervisor.
Para hacer eso, AWS Storage Gateway ofrece las siguientes formas para tranferir tus datos:
File gateways: permite utilizar los protocols Network File System (NFS) y Server Message Block (SMB) para almacenar datos en Amazon S3 y se almacenan en la caché local lo que permite un acceso de baja latencia.
Volume gateways: las pasarelas de volumen ofrecen volúmenes de almacenamiento respaldados por S3 que sus servidores locales pueden utilizar a través del protocolo iSCSI (Internet Small Computer System Interface)
Tape gateway: una pasarela de cinta imita la infraestructura tradicional de copia de seguridad en cinta. Funciona con las aplicaciones de aplicaciones de copia de seguridad comunes.
AWS Snowball
AWS Snowball es un dispositivo de hardware diseñado para mover cantidades masivas de datos entre su sitio y la nube de AWS en poco tiempo.
Algunos casos de uso comunes para Snowball incluyen los siguientes:
Migración de datos desde una oficina o centro de datos a la nube de AWS.
Transferir rápidamente una gran cantidad de datos hacia o desde S3 para fines de copia de seguridad o recuperación.
Distribuir grandes volúmenes de contenido a clientes y socios.
La idea de Snowball es que es más rápido enviar físicamente una gran cantidad de datos que transferirlos por la red. Por ejemplo, supongamos que quieres migrar una base de datos de 40 TB a AWS. Esa transferencia, incluso a través de una conexión ultrarrápida de 1 Gbps, tardaría más de 4 días.
Pero en su lugar, por una tarifa nominal, AWS le enviará un dispositivo Snowball. Simplemente hay que transferir tus archivos a él y enviarlo de vuelta. Cuando AWS lo recibe, transfiere los archivos de Snowball a uno o más cubos de S3.
No se cobra ninguna tasa de transferencia por importar archivos a S3, y una vez allí, están disponibles inmediatamente para ser utilizados por otros servicios de AWS.
